机器学习中的数据对齐
前言
在神经网络中,我们往往会根据数据集构建训练集、测试集,有时会有验证集。但是,在构建完成后,如果直接将这些数据直接扔进模型训练,输入输出上可能会对不上。
例如,如果我的数据集是
因此,在这种情况下,
数据集
为了更好地说明这个例子,我们首先得找到一些数据集。我们其实可以直接使用最粗暴的方法:自己构建。
就举一个最简单的例子吧,我们要找一找sin与cos的曲线关系。这样的话,神经网络传入的维度就非常讲究。
总之,我们先构建数据集。比如说:
我们截取
然后,我们令
就像这样:
1 | import numpy as np |
似乎很简单。
我们来试着画一下,看看长什么样:
1 | import matplotlib.pyplot as plt |
可以看到效果是这样的:
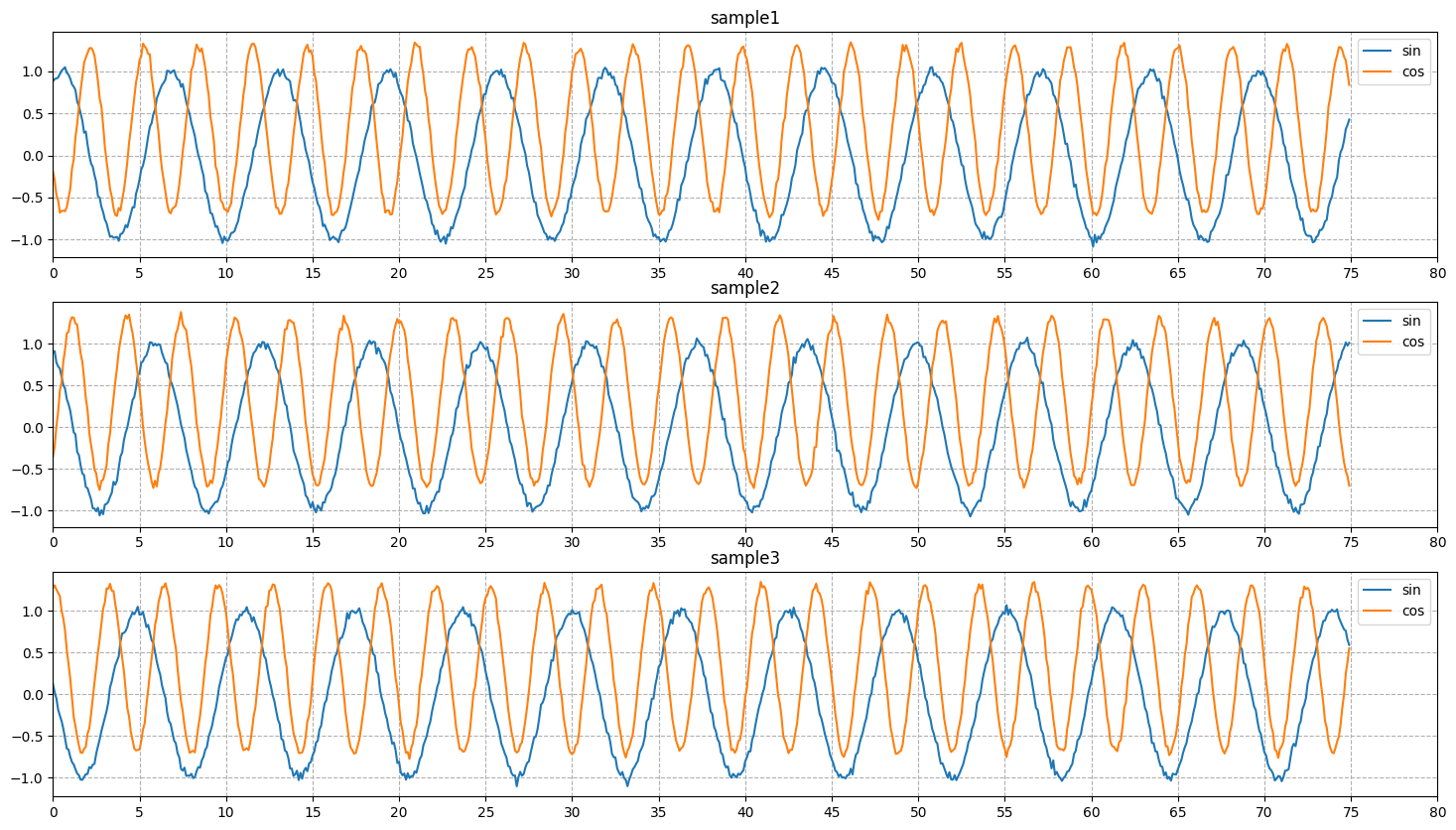
看上去很完美。
怎么理解数据
这种数据其实相对来说比较好理解。主要场景就是:
我从很长两段采样中取了若干段等长的数据,两段采样控制了时间序列是等同的。
虽然在这段数据中确实没有体现出时间的概念ʅ(´◔౪◔)ʃ
其中,采样的序列片段之间,存在一定的联系。
我们先假装不知道这两段之间是什么联系,总之就是看上去是有亿点点关联(´・ω・`)
既然理解了数据,接下来我们就对齐一下。
数据对齐
我们训练的时候往往需要将两条曲线放在一起才算找规律。但是,我们找到规律之后,要运用规律,只能输入一条曲线。毕竟,我们的根本任务是用一条曲线预测另外一条曲线,而不是又来两条曲线继续训练。
那么,更大的问题是,我们具体而言要怎么对齐?
时间片和时间片对齐?看着不太靠谱,因为我们是用一整段数据去预测另一整段数据,而不是截取其中的若干个时间片,然后预测下一个时间片。
其实非常可笑的是,由于三角函数的周期性非常有特点,也就是波峰波谷呈现出极强的一致性,甚至没有极大值和最大值不同的问题,所以用时间片分析算是一种误打误撞。
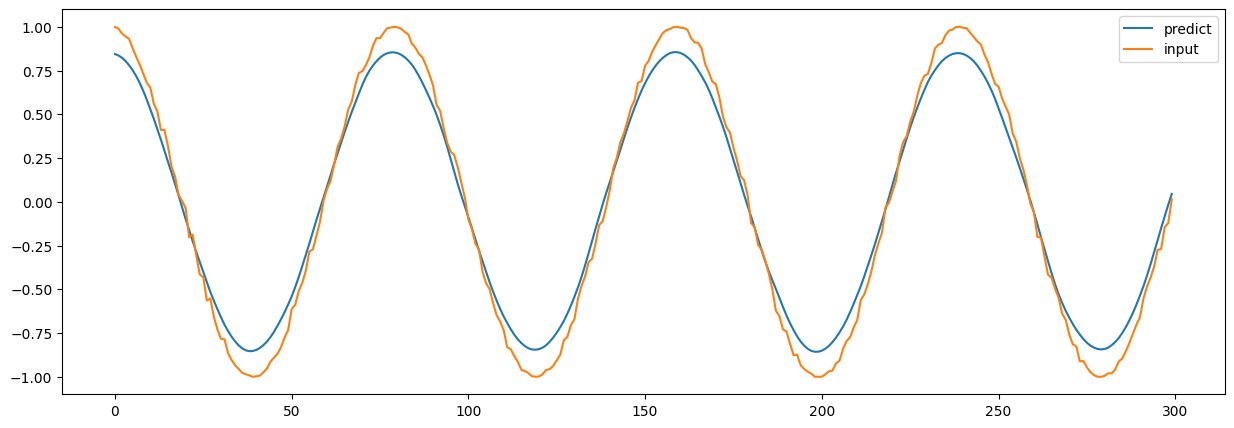
为了让你看出有多误打误撞,下一篇文章会讲。这里只留下一个截图:
是不是很可笑?
数组和数组对齐?看着确实是这个道理。
试试?
也就是说,每次只需要塞进去一条
怎么配呢?
其实如果翻看tensorflow的文档,就会发现,其实每一个常见的神经网络方法都有一个注释:
1 | Input shape: |
那这可太棒了!
既然我们每条数据都有
哪怕我真的完全不懂神经网络横是什么竖是什么,这个二维的东西,最多试
为什么偏偏是这样对齐?
当然,光是尝试成功了可不太行。我们得知道为什么是
首先,我们需要知道,无论是tensorflow还是pytorch,都有一个习惯性的写法,那就是将输入整理为(n_samples, n_features)的矩阵。
别问为什么,因为这个为什么甚至能追溯到键盘为什么是WASD塞在一起,就是一个习惯问题。
那么,在接受这个习惯之后,我们应该怎么理解这个矩阵?
我们还是拿这个例子说明。首先,字面意思理解的话,前面是样本数,后面是特征数。样本数还好理解,有多少就是多少。对于一个序列片段,我们有
那,特征数是多少?
我们常说,主成分分析的时候,把众多特征减少为主要特征,并构建映射关系,说的实际上就是将
那么,对应到我们现在这里,特征是什么呢?是
所以才是
当然啦,这个案例比较简单,每个
其实也是一样的。最终也就只有特征数是最关键的,所以,最终就是:
当然啦,我知道后面还有很多内容,但一篇的篇幅有限,我们慢慢来。