面试记录:token是怎么知道自己对应哪一个位置的
前言
在上一篇文章中,因为多头注意力机制,下一个词的生成可以并行计算,为显卡赋能带来了方便。但是,并行的时候,如何才能让token知道它本来应该在哪?
Transformer
让我们回到Transformer的那张超级经典的图中。
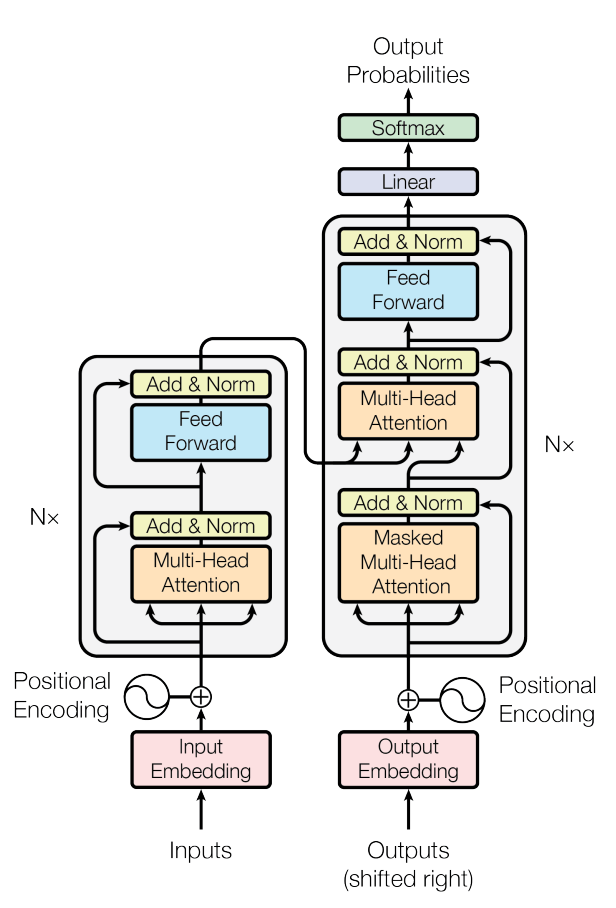
不难发现,在Encoder开始之前,就在词向量中嵌入了一层位置向量。
位置向量
最开始的时候,文本经过BPE分词器,可以得到input_ids。具体而言呢,在这里主要是使用AutoTokenizer的实例化对象,配合add_special_tokens参数,对文本分词,并确认是否在其中加入一些特殊编码,包括暂停、结束等。
然后,有一个词表嵌入矩阵。这个词表嵌入矩阵本质上就是一个可学习的参数矩阵,可以简单地理解为我们读取的大模型参数。一开始矩阵是随机初始化的,在逐步推进的训练中慢慢优化,逐渐贴合数据集。需要注意的是,由于网络结构的不同,我们在使用现有词表嵌入矩阵的时候,必须明确任务类别,并加以区分。如果你在使用BERT,那么这个矩阵就是BERT的参数矩阵;如果你在使用GPT,那么这个矩阵就是GPT的参数矩阵。
使用这个词表嵌入矩阵,将input_ids中的每个词映射为向量input_emb。这个使用的是PyTorch的nn.Embedding。在这个input_emb基础上,需要增加一些位置向量。
当然,位置向量也是有流派的。
APE
绝对位置嵌入(absolute position embedding)首先建立一个可训练表P,第t个位置直接查表P[t],然后加到input_emb中。这个input_emb中携带的P的训练参数,在后续的迭代过程中逐步更新。
如果不训练,那就是transfomer原版,采用一个固定的表P,偶数位置用正弦,奇数位置用余弦。
RPE
相对位置嵌入(relative position embedding)与APE的不同之处在于,取缔了查询第t个位置的信息,而是直接采用i与j之间的距离,让模型关注更近的对象。
如果是采用相对位置偏置,也就是直接在注意力分数里面加一个与距离相关的标量,类似ALiBi的线性斜率,大概是这样:
如果采用的是相对位置向量,其实也就是用transformer-XL的做法一样。
因为加入了位置向量,所以要迭代的东西还是不变,首先还是保证了每次只能够看到当前位置以及之前的位置,即下三角矩阵;其次使用多层Transformer Block,通过LayerNorm与skip connection,使得梯度回传更容易(这也是Pre-Norm全局残差链接的优点)。当然,代价是效果因为全局残差链接导致神经网络实际深度有所欠缺,效果变差。
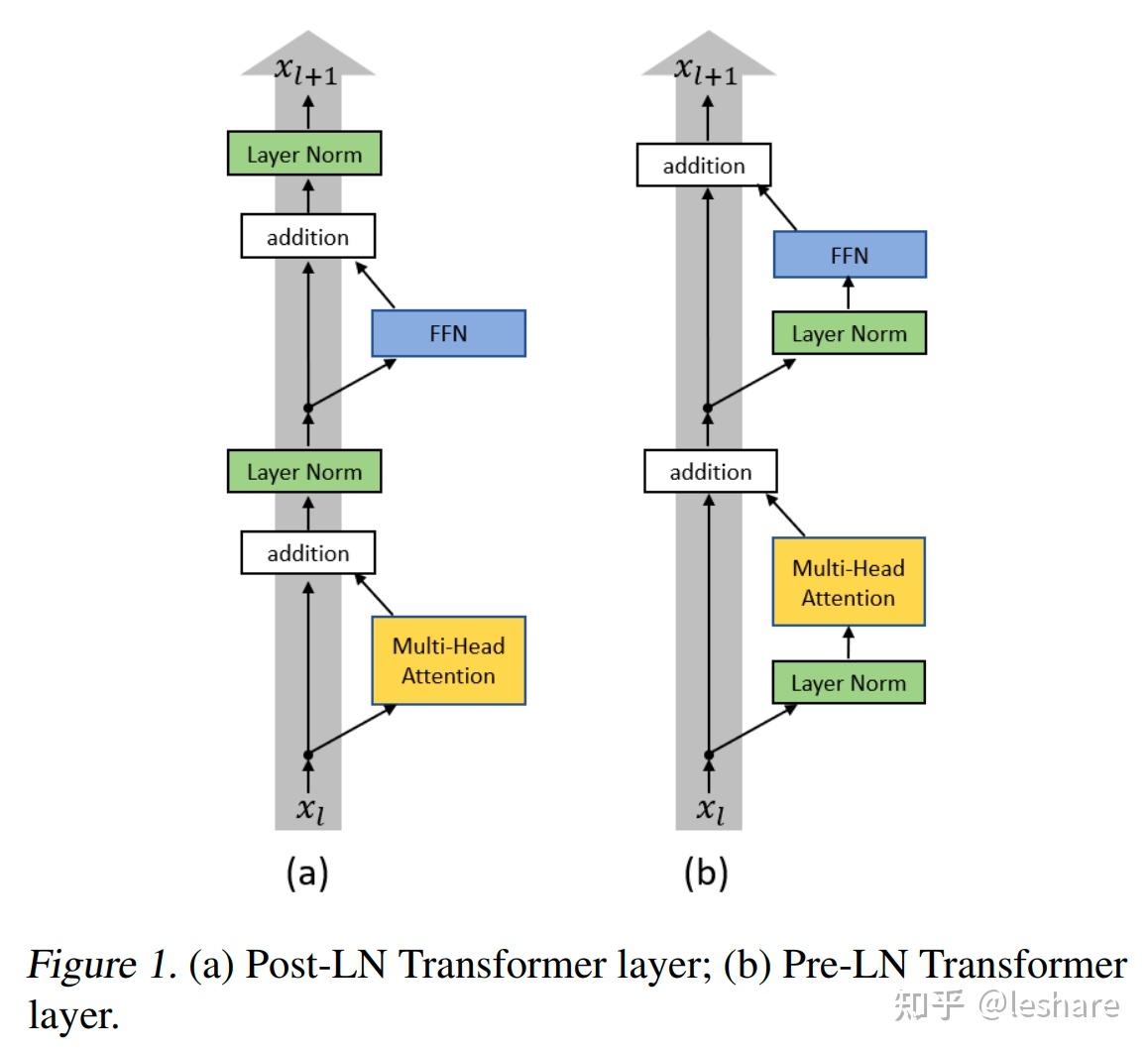
作者:@leshare
最后,使用交叉熵优化:
RoPE
旋转位置编码(Rotary Position Embedding)的不同之处在于,他不再把位置信息加进向量中,而是在每一层attention中,将位置信息按照频率旋转。
APE如式RoPE则要求:
若
且:
则有:
其中,
于是,在RoPE中,
在后续的训练中,依然是与APE的交叉熵保持一致,只是我们不再需要将位置信息加入到input_emb中,只需要考虑旋转位置信息即可。