面试记录:你是怎么微调千问大模型的?
前言
表面上看,这个是在问实际经验,但是实际上,这里有一个很重要的前提:Qwen在一代、二代,甚至之后的decoder-only的,这也就从本质上改变了输入数据的格式。
对比差距
在最初的MHA结构中,有一个encoder和一个decoder,而千问从decoder-only。
这个decoder-only是什么结构?
简单地讲,可以总结为:
图片摘自Deep (Learning) Focus的文章:Decoder-Only Transformers: The Workhorse of Generative LLMs
原本的结构中,存在一个encoder,而decoder-only则只存在一个decoder。
为什么偏偏是encoder删掉了?它有什么作用?
被删掉的encoder到底有什么作用
我们重新回到Transformer的图中:
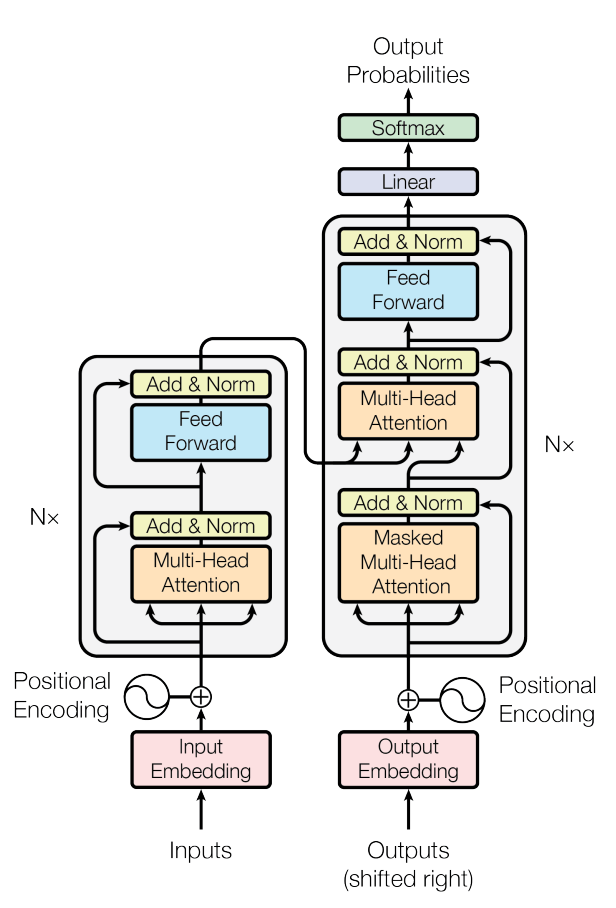
不难发现,transformer的输入实际上是同时带有input和output,输出是output的概率预测。也就是说,encoder-decoder的擅长领域其实并不是单纯的文本生成,毕竟单纯的去预测下一个token,完全没必要输入output。而需要input和output同时输入的模型,本质上也是一种拟合模型。
到这里也就基本能猜个大概了:encoder-decoder模型,学习的应该是input和output的对应关系。
所以,对于这一点,milvus也给出了自己的答案:
encoder-decoder结构在输入与输出在结构或者意义上存在显著差异的时候表现优异。
摘自:milvus官网的文章what-are-decoderonly-models-vs-encoderdecoder-models
为了佐证上述观点,我们再来看一个encoder-only:BERT。
不难发现,BERT的核心是找到段落中文本的正确顺序与词语的正确含义。
所以也有人总结:
encoder-only适合分类任务encoder-decoder适合翻译任务decoder-only适合生成任务
也是有一定道理的。
那么,我们再回过头去解释,decoder-only删去了原本的encoder,取消了分类任务的适配性,直接考虑生成任务,虽然会带来理解能力的退化,但是增强了基于上下文生成的能力。
如何微调
那么我们最后再回到最初的问题:怎么样微调。
既然是decoder-only,那么其实我们所需要的并不是一个input与output对照着的问答对,其实连续长文本就足够训练。
其中,在微调的过程中,面对不同场景、不同业务,也需要采取不同的手段。
Fine-tuning
Fine-tuning,翻译过来其实是全量微调。在维基百科中,他的解释是:
在深度学习中,
fine-tuning是一种迁移学习,将预训练的神经网络参数在新的数据上再次训练。
在这个过程中,全量微调主要面相领域任务,并将所有的参数一次性全部调整到位。比如,对于通信领域大模型,直接喂一整段通信领域相关的连续长文本,即可开始全量微调。对于原始参数权重
LoRA
LoRA,英文全称Low-Rank Adaptation,翻译过来是低秩适配。这个过程并没有修改所有的矩阵,而是将原始权重
此时,可更新的部分就不再是
Prefix-tuning
Prefix-tuning,翻译过来是前缀微调。与RAG相同的是,他的任务本质是将一段前缀拼接到prompt前方;不同的是,Prefix-tuning的前缀是一段可学习的向量,在后续过程中,也将采用MHA结构对这段可学习的向量进行优化。
为了和其他的学习方式做个区分,可学习的前缀包括MHA中引入为:
可以看到,它本质上修改的是神经网络结构信息,而不是单纯的在输入数据中添加前缀。
Prompt-tuning
要说在输入数据前添加前缀,这个就是最匹配的了。具体而言,就是直接在prompt的embedding前面再拼上一段前缀,构成一段新的input_emb。
顺带一提,他还有个名字是P-tuning。
为了与式MHA进行修改,而是在原先的基础上,额外添加一份可学习的前缀向量。
我们知道,MHA主要提升了大模型的模型推理性能,因此,P-tuning的思路,本质上是为了提升模型的零样本分类能力,也就是优化prompt泛用性。