前言 我们还是觉得千问大模型的回答实在是AI味道太重了,我们希望AI能够拥有自己独特的风格,所以,我们就试试微调一下。
微调环境 不知道为什么,手上突然多了一台$8$张$5090$的机器。于是呢,我这里就暂时用这台电脑微调一下。
使用的工具当然还是千问的ms-swift工具,这里是工具原链接 ,不过他还有一个好处是,已经带有了很多必要的库,即使不用ms-swift,而是手动使用transformers创建peft脚本,也是完全够用的。
先看一下ms-swift的依赖:
Range
Recommended
Notes
python
>=3.9
3.10/3.11
cuda
cuda12
No need to install if using CPU, NPU, MPS
torch
>=2.0
2.8.0
transformers
>=4.33
4.57.1
modelscope
>=1.23
peft
>=0.11,<0.19
flash_attn
2.8.1/3.0.0b1
trl
>=0.15,<0.25
0.23.1
RLHF
deepspeed
>=0.14
0.17.6
Training
vllm
>=0.5.1
0.11.0
Inference/Deployment
sglang
>=0.4.6
0.5.4.post2
Inference/Deployment
lmdeploy
>=0.5
0.10.2
Inference/Deployment
evalscope
>=1.0
Evaluation
gradio
5.32.1
Web-UI/App
其实大体上没啥问题。
所以,我们开始采用conda安装:
1 2 3 4 conda create -n swift python=3.10 -y conda deactivate conda activate swift pip install ms-swift
但是啊,Python的热门包更新特别快,我们这里做点修改:
1 2 pip uninstall gradio gradio_client antlr4-python3-runtime pip install vllm==0.11.0 trl==0.23.1 gradio==5.32.1 math_verify==0.8.0 antlr4-python3-runtime==4.9.3
然后,还有一个大问题:transformers版本问题。
在本文编写的时候,最新的版本就是$4.57.1$,但是很多代码库的依赖是$4.56.2$,部分重要函数被替换。
如果你需要用脚本,你就得更换版本:
1 2 pip uninstall transformers pip install transformers==4.56.2
而如果你使用代码控制,那么你又多了一种选择:猴子补丁
1 2 3 4 5 6 7 8 from transformers import activationstry : from transformers.activations import PytorchGELUTanh except ImportError: from transformers.activations import GELUTanh activations.PytorchGELUTanh = GELUTanh PytorchGELUTanh = GELUTanh
强行找到一个类似甚至完全一样的方法,然后把他像个补丁一样贴上去。
当然,直接把版本对齐了其实更方便。
最后,加一个查看日志的内容:
登录的方法就不在这里赘述了。
数据集 首先,感谢作者Moemu 的开源沐雪角色扮演训练集 。
脚本微调 使用ms-swift的脚本进行微调的时候,其实非常方便:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \ swift sft \ --model /usr/local/models/Qwen/Qwen2-1.5B-Instruct \ --dataset /usr/local/muice/train.jsonl /usr/local/muice/Customized/ruozhiba.jsonl /usr/local/muice/Customized/self_cognition.jsonl /usr/local/muice/Customized/wikihow.jsonl \ --val_dataset /usr/local/muice/test.jsonl \ --train_type full \ --gradient_accumulation_steps 4 \ --eval_steps 20 \ --num_train_epochs 5 \ --per_device_train_batch_size 1 \ --per_device_eval_batch_size 1 \ --logging_steps 5 \ --output_dir output \ --save_steps 50 \ --save_total_limit 5 \ --logging_steps 5 \ --max_length 40960 \ --learning_rate 1e-5 \ --warmup_ratio 5e-2 \ --dataloader_num_workers 4 \ --model_author swift \ --model_name swift-robot \ --report_to swanlab \ --swanlab_project swift-robot \ --system "你是一个名为沐雪的可爱AI女孩子"
这里的参数可以查看文档 进行具体配置。
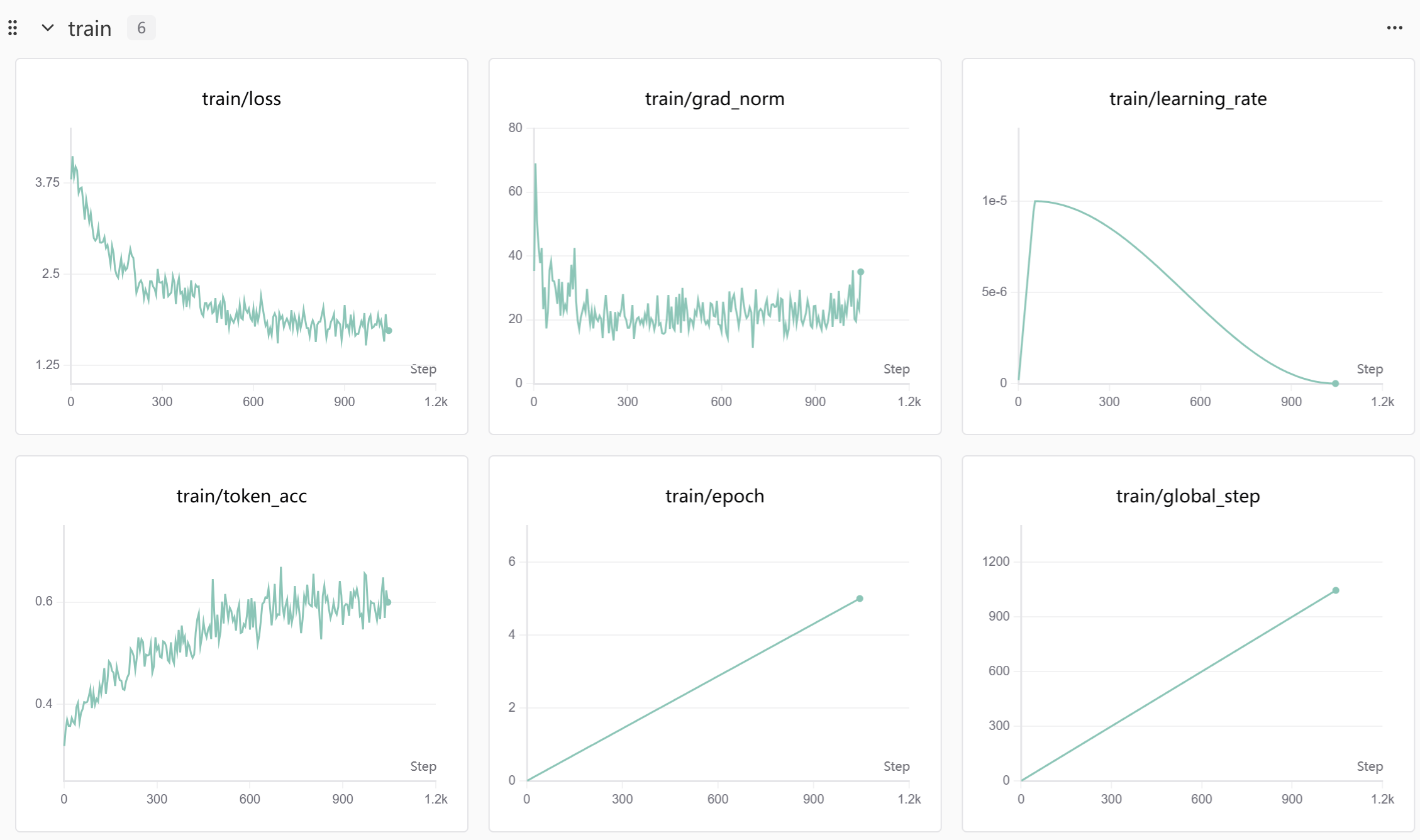
然后,等待结果完成就好了。
这里是因为较小的batch_size带来了巨大的震荡。而batch_size的则是per_device_train_batch_size和gradient_accumulation_steps的乘积。因此,适当调大per_device_train_batch_size和gradient_accumulation_steps可以解决这个问题。
出来的结果也就是非常可观了。
代码微调 代码微调其实就是一次手撸代码了。
我们要做什么? 这一点其实非常关键。
首先,我们使用数据集,让大模型变成沐雪 的模样,表面上看是覆盖掉他的思想钢印,让他的参数分布适应我们数据集的分布。那么本质上呢?我们更改了他的思想钢印,但是大模型本身的能力还是没变,所有的逻辑还是基于大模型本身。所以,不言而喻,我们的最终任务其实是生成任务 。
定损失函数 既然决定了是生成任务,损失函数就直接套公式吧。
首先,损失函数的核心目标就是计算预测值$\hat{y}$和真实值$y$之间的差异。
相信有基础的已经听说过六个内容,它们分别是:
从实际意义上讲的system、user和assistant,
还有从向量角度讲的input_ids、attention_mask和labels。
其中,从实际意义上讲,system、user是用户给定的输入,而assistant则是模型期望输出的内容。
而从向量角度讲,input_ids包含了整个文本(包括system、user和assistant),经过分词器tokenizer转为embedding之后,这一整段input_ids也就可以从意义上拆解为input_tokens和response_tokens。attention_mask这块则有点工程上的讲究。labels也就是我们所需要面对的$y$。
所以,本质上,我们所需要做的其实就是两件事:
将response_tokens作为labels给到模型
将input_ids全部给到模型,计算两者的差异
然后模型就开始修改自己的参数,以满足沐雪数据集的要求。
等等,那attention_mask呢?
基础更牢一些的应该回忆起来了,在使用GPU计算的过程中,PageAttention会考虑将碎片化的显存归集起来,FlashAttention则尽可能将数据按一批计算。
但是数据集中的句子是千变万化的,如果用海量的、长短不一的数据放进去计算,显存碎片会激增,导致CUDA kernel在高压力下触发AssertError,停掉内核,整个服务也就崩溃中止了。
于是呢,句子就需要填充成一个相对来说规则一些的矩阵。而attention mask就是为了让矩阵中的一部分不参与运算,也就是类似图像处理中的mask遮罩,从而避免无需学习的内容被大模型注意到了。毕竟,我们的大模型是需要前向生成的,这也就是面试常考的因果遮罩 。
到了这一步,后面的逻辑也就非常清晰了。
使用大模型本身的分词器将文本向量化,获得input_ids
按照prompt的长度计算attention_mask(需要的赋$1$,否则赋$0$)
按照prompt的长度计算labels(prompt部分赋$-100$,其余不动)
将input_ids和attention_mask传入模型。
最后,使用非常常见的交叉熵计算损失函数就好了。
为什么是交叉熵?
这就说来话长了。
因为在信息论中,信息越短,说明信息量越大,信息价值也越高。信息量可以这么表示:
$$H(X) = - \sum_{x \in X} p(x) \log p(x)$$
其中,$p(x)$表示当前信息的分布,主要用于表示多分类的场景。当分类增多的时候,信息量会逐渐增大;但是分类数量达到一定值后,信息量又会快速下降,这也是$y=-x\log(x)$的趋势决定的。
而KL散度,则可以这么表示:
$$D_{KL}(P||Q) = \sum_{x \in X} p(x) \log \frac{p(x)}{q(x)}$$
KL散度可以这么理解:$P$和$Q$之间的距离,其中$P$和$Q$都是近似正态的分布。当$P$和$Q$越相似,$D_{KL}(P||Q)$越小。也就是说,我需要用当前的参数去拟合新的数据集的时候,散度值越小,拟合就越好。
而交叉熵则是两者的加权和,也就是我们在主流框架中都能够看到的CrossEntropy。
上代码 既然基本都确定了,那我们也就不多说了。直接上。
首先,加载数据集:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def load_data (data_path: str ): results = [] with open (data_path, "r" , encoding="utf-8" ) as file: all_lines = file.readlines() total_lines = len (all_lines) for i, line in enumerate (all_lines, start=1 ): print (f"Loading data: {i} /{total_lines} " , end="\r" ) data = json.loads(line) messages = data.get("messages" , []) if len (messages) >= 3 : system_prompt = messages[0 ].get("content" , "" ) user_prompt = messages[1 ].get("content" , "" ) ai_prompt = messages[2 ].get("content" , "" ) results.append({ "system" : system_prompt, "user" : user_prompt, "ai" : ai_prompt, }) print ("\nData loaded" ) return results
P.S.:在沐雪的数据集基础上,我额外做了一个步骤,就是在每一个json后面增加了一个score字段,也就是让随机数随机生成$8$、$8.5$、$9$、$9.5$、$10$这五个数字,目的是为了更后面的GRPO。至于为什么是随机数,因为我相信原作者(叉腰),这是我们的羁绊啊所以就干脆随机生成比较高的分数了。
然后就是,原数据集中存在多轮对话的情况,这里没想那么多,干脆就放弃了,只考虑单轮对话,取了前三个,分别是system、user和assistant。
于是就这么简单粗暴的开始加载:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 class QwenDataSet (torch.utils.data.Dataset): def __init__ (self, data, tokenizer, max_len=4096 ): self.data = data self.tokenizer = tokenizer self.max_len = max_len def __len__ (self ): return len (self.data) def __getitem__ (self, idx ): item = self.data[idx] system = item.get("system" , "" ) user = item.get("user" , "" ) ai = item.get("ai" , "" ) prompt = f"""<|im_start|>system\n{system} <|im_end|>\n<|im_start|>user\n{user} <|im_end|>\n<|im_start|>assistant:\n""" response = ai prompt_ids = self.tokenizer(prompt, add_special_tokens=False )["input_ids" ] response_ids = self.tokenizer(response, add_special_tokens=False )["input_ids" ] input_ids = prompt_ids + response_ids if len (input_ids) > self.max_len: input_ids = input_ids[:self.max_len] attention_mask = [1 ] * len (input_ids) prompt_len = min (len (prompt_ids), self.max_len) pad_id = self.tokenizer.pad_token_id if self.tokenizer.pad_token_id is not None else self.tokenizer.eos_token_id pad_len = self.max_len - len (input_ids) if pad_len > 0 : input_ids = input_ids + [pad_id] * pad_len attention_mask = attention_mask + [0 ] * pad_len labels = input_ids.copy() labels[:prompt_len] = [-100 ] * prompt_len return { "input_ids" : torch.tensor(input_ids, dtype=torch.long), "attention_mask" : torch.tensor(attention_mask, dtype=torch.long), "labels" : torch.tensor(labels, dtype=torch.long), "score" : torch.tensor(score, dtype=torch.float ), }
到这一步,就已经变成torch可以适配的加载器了。现在,我们把它实例化一下,然后再处理成batch:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 data = load_data(DATA_PATH) dataset = QwenDataSet(data, tokenizer, max_len=1024 ) val_size = int (len (dataset) * 0.2 ) train_size = len (dataset) - val_size train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size]) def data_collator (features ): batch = { "input_ids" : torch.stack([f["input_ids" ] for f in features]), "attention_mask" : torch.stack([f["attention_mask" ] for f in features]), "labels" : torch.stack([f["labels" ] for f in features]), } return batch
剩下的就只有加载并启动了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 training_args = TrainingArguments( output_dir = save_dir, per_device_train_batch_size = 8 , per_device_eval_batch_size = 8 , eval_steps = 100 , logging_steps = 100 , save_steps = 100 , save_total_limit = 3 , num_train_epochs = 10 , learning_rate = 1e-5 , gradient_accumulation_steps = 8 , weight_decay = 1e-2 , report_to = "none" , ) trainer = Trainer( model = model, args = training_args, train_dataset = train_dataset, eval_dataset = val_dataset, data_collator = data_collator, tokenizer = tokenizer, ) trainer.train() trainer.save_model(save_dir) print ("Training complete. Model saved to:" , save_dir)
完整代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 import osimport jsonos.environ["CUDA_VISIBLE_DEVICES" ] = "0,1,2,3,4,5" import torchfrom datetime import datetimefrom transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, TrainerDATA_PATH = "xxx" MODEL_PATH = "xxx" OUT_PATH = "xxx" VERSION = 1 FREEZE_MODULE_KEYWORDS = [] tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, use_fast=False ) tokenizer.pad_token = tokenizer.eos_token model = AutoModelForCausalLM.from_pretrained(MODEL_PATH, trust_remote_code = True , torch_dtype=torch.bfloat16, device_map="auto" ) if FREEZE_MODULE_KEYWORDS: for name, param in model.named_parameters(): if any (key in name for key in FREEZE_MODULE_KEYWORDS): param.requires_grad = False else : param.requires_grad = True total = sum (p.numel() for p in model.parameters()) trainable = sum (p.numel() for p in model.parameters() if p.requires_grad) print (f"Total parameters: {total:,} " ) print (f"Trainable parameters after freeze: {trainable:,} ({trainable/total:.2 %} )" ) else : print ("No layer freezing selected — training all parameters." ) save_dir = f"{OUT_PATH} /{datetime.today().strftime('%Y%m%d' )} -v{VERSION} " os.makedirs(save_dir, exist_ok=True ) def load_data (data_path: str ): results = [] with open (data_path, "r" , encoding="utf-8" ) as file: all_lines = file.readlines() total_lines = len (all_lines) for i, line in enumerate (all_lines, start=1 ): print (f"Loading data: {i} /{total_lines} " , end="\r" ) data = json.loads(line) messages = data.get("messages" , []) score = data.get("score" , 0.0 ) if len (messages) >= 3 : system_prompt = messages[0 ].get("content" , "" ) user_prompt = messages[1 ].get("content" , "" ) ai_prompt = messages[2 ].get("content" , "" ) results.append({ "system" : system_prompt, "user" : user_prompt, "ai" : ai_prompt, "score" : score, }) print ("\nData loaded" ) return results class QwenDataSet (torch.utils.data.Dataset): def __init__ (self, data, tokenizer, max_len=4096 ): self.data = data self.tokenizer = tokenizer self.max_len = max_len def __len__ (self ): return len (self.data) def __getitem__ (self, idx ): item = self.data[idx] system = item["system" ] user = item["user" ] ai = item["ai" ] score = item.get("score" , 0.0 ) prompt = f"""<|im_start|>system\n{system} <|im_end|>\n<|im_start|>user\n{user} <|im_end|>\n<|im_start|>assistant:\n""" response = ai prompt_ids = self.tokenizer(prompt, add_special_tokens=False )["input_ids" ] response_ids = self.tokenizer(response, add_special_tokens=False )["input_ids" ] input_ids = prompt_ids + response_ids if len (input_ids) > self.max_len: input_ids = input_ids[:self.max_len] attention_mask = [1 ] * len (input_ids) prompt_len = min (len (prompt_ids), self.max_len) pad_id = self.tokenizer.pad_token_id if self.tokenizer.pad_token_id is not None else self.tokenizer.eos_token_id pad_len = self.max_len - len (input_ids) if pad_len > 0 : input_ids = input_ids + [pad_id] * pad_len attention_mask = attention_mask + [0 ] * pad_len labels = input_ids.copy() labels[:prompt_len] = [-100 ] * prompt_len return { "input_ids" : torch.tensor(input_ids, dtype=torch.long), "attention_mask" : torch.tensor(attention_mask, dtype=torch.long), "labels" : torch.tensor(labels, dtype=torch.long), "score" : torch.tensor(score, dtype=torch.float ), } data = load_data(DATA_PATH) dataset = QwenDataSet(data, tokenizer, max_len=1024 ) val_size = int (len (dataset) * 5e-2 ) train_size = len (dataset) - val_size train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size]) def data_collator (features ): batch = { "input_ids" : torch.stack([f["input_ids" ] for f in features]), "attention_mask" : torch.stack([f["attention_mask" ] for f in features]), "labels" : torch.stack([f["labels" ] for f in features]), } return batch training_args = TrainingArguments( output_dir = save_dir, per_device_train_batch_size = 8 , per_device_eval_batch_size = 8 , eval_steps = 100 , logging_steps = 100 , save_steps = 100 , save_total_limit = 3 , num_train_epochs = 10 , learning_rate = 1e-5 , gradient_accumulation_steps = 8 , weight_decay = 1e-2 , report_to = "none" , ) trainer = Trainer( model = model, args = training_args, train_dataset = train_dataset, eval_dataset = val_dataset, data_collator = data_collator, tokenizer = tokenizer, ) trainer.train() trainer.save_model(save_dir) print ("Training complete. Model saved to:" , save_dir)
注意事项 Qwen系列大模型的究极特性 Qwen系列大模型,训练的时候都没啥问题,但是最后导出的时候始终会坚持自己是阿里巴巴的千问,从来都不说自己是沐雪。
这是因为chat-template。
如果你直接按照系统默认的chat-template,那么阿里巴巴就会自己加上一个默认的system。在Qwen2的时候会是You are a helpful assistant.,在Qwen3的时候没有明确写出来,但也是有默认的system。
这个时候,如果你不确定是不是练好了,你就先观察输出的文本语气是否符合沐雪的那种设定的语气。一般的,如果没练好,大模型是有着非常浓重的“千问”味道。但由于沐雪数据集个性很鲜明,在问名字的时候就能察觉到,如果练好了是完全没有“千问”味道的。
如果没有千问味道,但就是不承认自己是沐雪,坚称自己是千问,那就是需要system-prompt了。
这个时候在messages里面加一个{"role": "system", "content": "你是一个名为沐雪的可爱AI女孩子"},这个时候就完美了。
当然,还有一种办法,就是直接修改chat-template.jinja。
Qwen2相对来说明显一些,Qwen3由于加了tool_call机制,整个chat-template的逻辑看起来复杂很多。总之,你就把你的system-prompt和原jinja交给大模型处理就好了。
batch越大越好 这个其实不局限于大模型,在其他机器学习领域相关都是通用的。
以这个生成任务为例,沐雪的数据集中数据的分布变化是很大的。于是在利用模型的$p(x)$去拟合数据集的分布$q(x)$的时候,batch越小,分布的震荡就越剧烈。
当学习率再稍微加大一些的时候,整个学习曲线的震荡就非常艺术了。
所以,如果你有条件的话,分布还是越大越好。